
A jornada histórica do DevOps não é um evento isolado na cronologia da computação, mas sim o ápice de uma evolução nas metodologias de trabalho que busca harmonizar a velocidade da inovação com a estabilidade operacional. Para compreendermos sua essência, precisamos retroceder às raízes da manufatura enxuta, especificamente ao Sistema Toyota de Produção no Japão pós-Segunda Guerra Mundial. Naquela era, a indústria automobilística enfrentava o desafio de produzir com alta qualidade e baixo desperdício, o que deu origem a conceitos como o Just-in-Time e o Kanban. Essas filosofias priorizavam a eficiência do fluxo, a eliminação de gargalos e a colaboração estreita entre todas as partes da linha de montagem, princípios que, décadas depois, seriam transplantados para o mundo do desenvolvimento de software para resolver a crescente crise de entrega tecnológica.
Antes do surgimento do termo DevOps, o cenário do desenvolvimento de software era caracterizado pela existência de silos rígidos e pelo modelo em cascata, o famoso Waterfall. Nesse sistema, os desenvolvedores trabalhavam isolados por meses na criação de funcionalidades e, ao final, “jogavam” o código por cima de uma muralha para a equipe de operações, que tinha a árdua tarefa de colocar aquilo para funcionar em servidores reais. Esse isolamento gerava a chamada muralha da confusão: os desenvolvedores eram incentivados pela agilidade e mudança, enquanto os operadores eram medidos pela estabilidade e resistência a alterações. O resultado eram ciclos de lançamento lentos, repletos de erros manuais e um ambiente de trabalho estressante, onde o sucesso de um significava o fracasso do outro.
A virada de chave ocorreu no final da década de 2000, impulsionada por profissionais visionários como Patrick Debois e Andrew Shafer, que começaram a debater a necessidade de integrar o desenvolvimento com as operações. O marco definitivo foi a conferência Velocity em 2009, onde John Allspaw e Paul Hammond apresentaram o histórico caso de como o Flickr realizava dez ou mais deploys por dia através da colaboração mútua. Esse evento provou que a velocidade e a estabilidade não eram opostas, mas sim dependentes uma da outra. A partir dali, o termo DevOps consolidou-se não como um software que se compra, mas como uma mudança cultural profunda, focada na automação, no compartilhamento de responsabilidades e na melhoria contínua, permitindo que as empresas acompanhassem o ritmo frenético da economia digital contemporânea.
O coração do DevOps não reside nas ferramentas tecnológicas, mas sim em uma transformação cultural que redefine como as pessoas interagem dentro de uma organização de tecnologia. Essa mudança exige o desmantelamento dos silos departamentais onde o desenvolvimento e as operações funcionavam como entidades distintas e, muitas vezes, antagônicas. Em uma cultura DevOps, a responsabilidade pelo produto final é compartilhada desde a primeira linha de código até a manutenção do sistema em produção. Isso significa que um desenvolvedor não considera sua tarefa concluída apenas quando o código compila em sua máquina, mas sim quando ele está gerando valor real para o usuário final de forma estável. Essa mentalidade de empatia e colaboração é o que permite a agilidade necessária para responder às mudanças do mercado.
Um exemplo prático dessa cultura pode ser visto em uma equipe de desenvolvimento de um aplicativo de entregas. Antes do DevOps, se o sistema caísse durante um pico de pedidos, a equipe de operações passaria horas tentando descobrir se o problema era um erro de código ou uma falha de servidor, enquanto os desenvolvedores já estariam focados em outra tarefa. Em um ambiente DevOps, ambas as equipes utilizam ferramentas de monitoramento compartilhadas e participam juntas da resolução de incidentes. Ao trabalharem juntas, a equipe de operações fornece feedback constante sobre como o código se comporta sob carga, permitindo que os desenvolvedores criem softwares mais resilientes. Essa troca de conhecimentos transforma o ambiente de “quem é a culpa?” para “como podemos melhorar o sistema?”.
A transparência é outro pilar fundamental dessa cultura. No DevOps, as métricas de sucesso e os fracassos são visíveis para todos, o que fomenta um ambiente de aprendizado contínuo. Em vez de punir erros individuais, a organização foca em entender as falhas sistêmicas que permitiram que o erro ocorresse. Se uma atualização causou lentidão no site, a equipe realiza uma retrospectiva sem busca por culpados, focando em como automatizar testes para que esse problema específico nunca mais chegue ao cliente. Essa segurança psicológica é o que impulsiona a inovação, pois as pessoas sentem-se encorajadas a testar novas ideias sabendo que existem salvaguardas e um time que as apoia, resultando em um ciclo de entrega mais humano e eficiente.
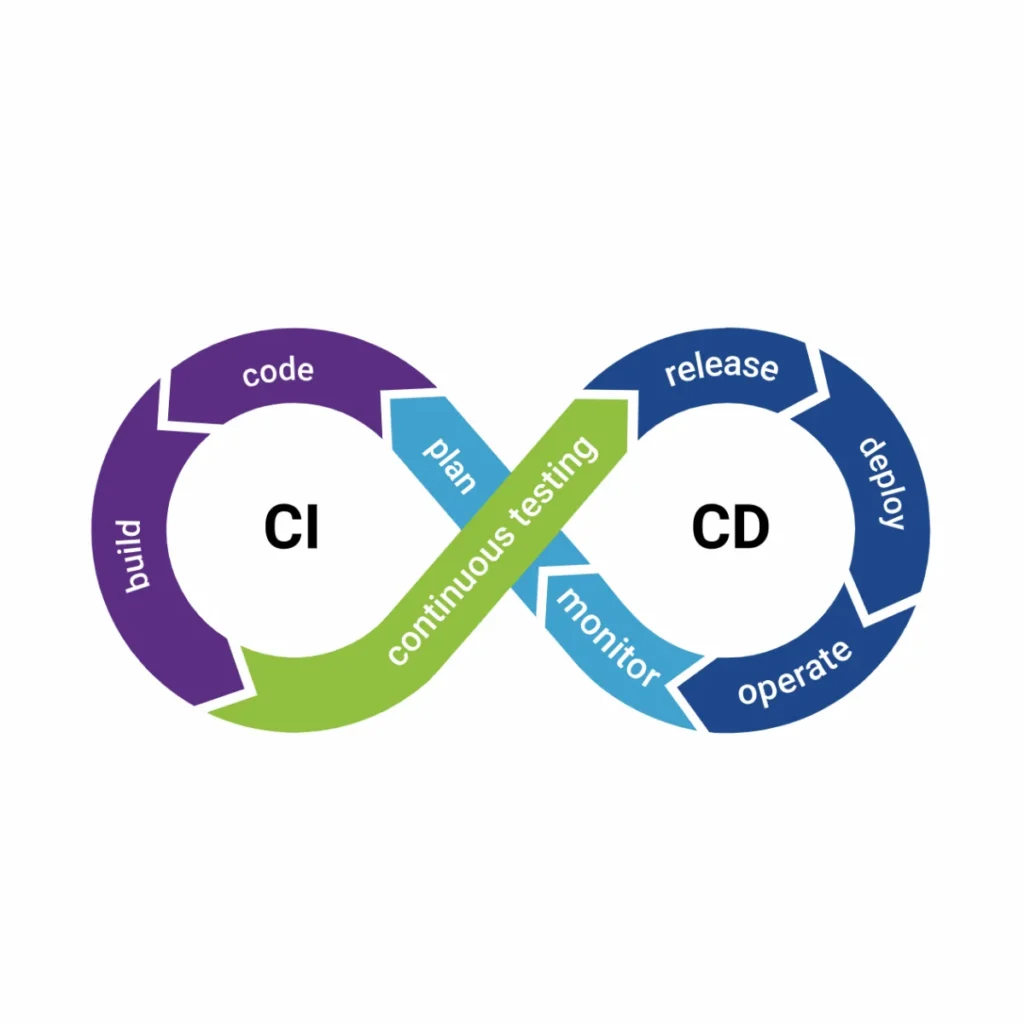
A Integração Contínua, ou CI, é a prática técnica que sustenta a agilidade do DevOps, focando na integração frequente do código de vários desenvolvedores em um repositório central. No modelo tradicional, os programadores mantinham ramificações de código longas e isoladas, o que resultava no temido “inferno da integração” quando tentavam juntar tudo ao final de semanas de trabalho. Com a CI, os desenvolvedores integram seu trabalho diariamente, ou até várias vezes ao dia. Cada integração é verificada automaticamente por uma bateria de testes e processos de compilação, garantindo que o novo código não quebre as funcionalidades já existentes. Esse processo transforma o repositório em uma fonte única da verdade, sempre pronta para ser validada.
Imagine uma plataforma de streaming onde dezenas de desenvolvedores trabalham simultaneamente em novas funcionalidades, como um botão de “pular introdução” e uma nova interface de busca. Sem a Integração Contínua, a união dessas duas frentes poderia gerar conflitos imprevisíveis que só seriam detectados dias depois. Com a CI, assim que o desenvolvedor envia sua parte do código para o repositório, um servidor de automação, como o Jenkins ou o GitHub Actions, inicia imediatamente a execução de testes unitários. Se o novo código afetar a performance da busca, o sistema emite um alerta instantâneo, e o erro é corrigido enquanto o contexto daquela tarefa ainda está fresco na mente do programador. Isso reduz drasticamente o custo de correção de bugs, que é exponencialmente maior quando detectados em fases tardias.
Além da detecção de erros, a Integração Contínua promove a padronização e a disciplina técnica. As ferramentas de CI podem incluir verificações de estilo de código (linting) e análises estáticas de segurança, garantindo que todo o software produzido pela empresa siga os mesmos critérios de qualidade, independentemente de quem o escreveu. Isso cria uma base de código limpa e compreensível para toda a equipe. No dia a dia de um pequeno negócio de tecnologia, a CI permite que a equipe foque no que realmente importa: a criação de valor. Em vez de gastar horas em reuniões de sincronização manual de código, os profissionais confiam no pipeline automatizado como um guardião silencioso da integridade do produto, permitindo lançamentos mais frequentes e com menor risco.
A Entrega Contínua (Continuous Delivery) e a Implantação Contínua (Continuous Deployment) são as extensões naturais da integração, focando em como o software validado chega aos ambientes de teste e produção. Na Entrega Contínua, o pipeline DevOps garante que o código esteja sempre em um estado “implantável”, o que significa que, a qualquer momento, o negócio pode decidir lançar a nova versão com o clique de um botão. Já na Implantação Contínua, cada alteração que passa nos testes automatizados é enviada automaticamente para o ambiente de produção, sem intervenção humana manual. Essas práticas eliminam os processos burocráticos e os lançamentos “big bang” que costumavam ocorrer a cada seis meses, substituindo-os por um fluxo constante de pequenas melhorias.
Considere uma loja virtual que deseja testar uma nova promoção relâmpago. No modelo antigo, lançar essa mudança exigiria uma janela de manutenção de madrugada e uma série de comandos manuais complexos nos servidores. Com o CD, a alteração é enviada para o ambiente de teste automaticamente; após a validação visual da equipe de marketing, a promoção é promovida para produção de forma transparente. Essa velocidade permite que a empresa responda em tempo real às ações da concorrência. O uso de técnicas como o “Blue-Green Deployment” ou “Canary Releases” torna esse processo seguro. No Blue-Green, uma nova versão do site é ligada em paralelo à antiga; se algo der errado, o tráfego é redirecionado de volta para a versão estável instantaneamente, minimizando o impacto negativo sobre os clientes.
Para o sucesso do CD, a infraestrutura deve ser tratada como código (IaC). Isso significa que as configurações de servidores, bancos de dados e redes são escritas em arquivos de texto e versionadas junto com o código do software. Se um desenvolvedor precisa de mais memória no servidor para uma nova funcionalidade, ele altera o script de infraestrutura, e o pipeline de CD se encarrega de provisionar os recursos necessários. Essa automação elimina a inconsistência entre os ambientes de desenvolvimento e produção, o famoso “na minha máquina funciona”. Ao automatizar o caminho até o usuário, as empresas reduzem drasticamente o tempo de colocação no mercado (time-to-market) e transformam o lançamento de software de um evento heroico e perigoso em um processo rotineiro, previsível e entediante, no melhor sentido da palavra.
Uma estratégia DevOps de sucesso não termina quando o software chega à produção; na verdade, um novo ciclo se inicia com o monitoramento contínuo e a coleta de feedback em tempo real. O monitoramento em DevOps vai além de saber se o servidor está ligado; trata-se de observar o comportamento do usuário, o desempenho das funcionalidades e a saúde técnica da aplicação sob condições reais. Sem esses dados, a equipe estaria trabalhando no escuro, baseando-se em suposições em vez de fatos. As ferramentas de monitoramento fornecem painéis visuais que mostram desde a taxa de erro em uma transação financeira até o tempo médio que um cliente leva para concluir uma compra, permitindo uma resposta proativa a problemas antes mesmo que os usuários percebam.
Um exemplo prático de monitoramento eficaz ocorre em um sistema de banco digital. Se o tempo de resposta para transferências via PIX aumenta em alguns milissegundos, o sistema de alerta notifica as equipes de desenvolvimento e operações simultaneamente. Através do rastreamento distribuído e da análise de logs centralizada, a equipe consegue identificar que o problema está em um serviço específico de validação de CPF. Como o DevOps prega a colaboração, o desenvolvedor que escreveu o código de validação e o operador que gerencia o banco de dados analisam os dados juntos, aplicando uma correção em minutos. Esse feedback de produção é o que alimenta o próximo planejamento (Plan) no ciclo DevOps, garantindo que as melhorias sejam baseadas na experiência real do usuário.
Além do monitoramento técnico, o feedback do usuário final é integrado diretamente ao fluxo de desenvolvimento. Testes A/B, onde duas versões de uma página são exibidas para grupos diferentes de clientes, permitem medir qual design gera mais conversão com base em dados concretos. Se os dados mostrarem que os clientes abandonam o carrinho quando o botão de frete é cinza, a equipe prioriza a mudança de cor no próximo ciclo de integração. O monitoramento transforma o software em uma entidade viva que aprende e evolui constantemente. Essa vigilância compartilhada fortalece a confiança entre as equipes e o negócio, pois todos sabem exatamente como o sistema está performando e onde residem as oportunidades de inovação, fechando o loop da melhoria contínua que define o DevOps.
Em um mundo onde as ameaças digitais evoluem na mesma velocidade que as funcionalidades, a segurança não pode ser um apêndice ao final do projeto. O conceito de DevSecOps propõe a integração da segurança em todas as fases do pipeline de entrega, movendo essa responsabilidade para a esquerda (Shift Left). Isso significa que as preocupações com proteção de dados, vulnerabilidades e conformidade são discutidas desde a fase de planejamento e validadas automaticamente durante a integração e implantação. Em vez de um departamento de segurança que atua como um portão que bloqueia lançamentos, a segurança torna-se uma competência compartilhada que empodera os desenvolvedores a criarem softwares intrinsecamente seguros.
Na prática, o DevSecOps utiliza ferramentas de Análise Estática de Segurança de Aplicação (SAST) que examinam o código-fonte em busca de falhas conhecidas, como brechas de injeção de SQL, no momento em que o desenvolvedor faz o commit. Se uma vulnerabilidade é detectada, o pipeline de Integração Contínua é interrompido, e o programador recebe um feedback imediato sobre como corrigir o problema. Além disso, testes dinâmicos (DAST) simulam ataques ao sistema em execução nos ambientes de teste, identificando falhas que só aparecem em tempo de execução. Imagine um portal de educação que lida com dados sensíveis de alunos; ao adotar o DevSecOps, cada nova funcionalidade de cadastro é submetida a testes automáticos de criptografia e controle de acesso antes mesmo de ser vista por qualquer pessoa externa.
A abordagem DevSecOps também foca na segurança da infraestrutura e das bibliotecas de terceiros. Com o uso extensivo de componentes de código aberto, é vital monitorar se as versões utilizadas possuem vulnerabilidades publicadas. Ferramentas automatizadas verificam todas as dependências do projeto e sugerem atualizações seguras de forma proativa. O resultado é um sistema robusto que resiste a ataques por design, e não por sorte. Ao integrar a segurança no DNA do DevOps, a organização não apenas protege sua reputação e cumpre regulamentações como a LGPD, mas também ganha velocidade, pois os problemas de segurança são resolvidos quando são pequenos e fáceis de tratar, evitando crises de larga escala que paralisariam o negócio.
A automação de testes é o alicerce técnico que permite que o DevOps funcione sem comprometer a qualidade do software. Em um ciclo de entrega rápida, o teste manual é inviável, pois se torna um gargalo que atrasa todo o processo e está sujeito a falhas humanas. O DevOps exige uma pirâmide de testes bem estruturada, começando por milhares de testes unitários rápidos, seguidos por testes de integração que verificam a comunicação entre módulos, e culminando em testes de ponta a ponta (E2E) que simulam a jornada completa do usuário. Essa rede de proteção automatizada dá à equipe a confiança necessária para realizar alterações profundas no sistema, sabendo que qualquer regressão será detectada em segundos pelo pipeline.
Um exemplo cotidiano da importância da automação de testes pode ser observado em um aplicativo de gerenciamento financeiro pessoal. O desenvolvedor precisa alterar a lógica de cálculo de juros compostos. Sem testes automatizados, ele teria que testar manualmente dezenas de cenários para garantir que o novo cálculo não afetou o saldo das contas antigas. Com uma suíte de testes unitários robusta, ele roda o script e, em menos de um minuto, valida todos os cenários possíveis. Se uma regra de arredondamento estiver incorreta, o teste falha e aponta exatamente a linha do erro. Essa agilidade permite que a equipe mantenha o foco na inovação, pois o trabalho mecânico de verificação é delegado às máquinas, garantindo que o software entregue seja sempre confiável.
Para que a automação seja eficaz, os testes devem ser escritos junto com o código, utilizando práticas como o Desenvolvimento Orientado a Testes (TDD). Além dos testes funcionais, o DevOps inclui testes automatizados de performance e carga, verificando se o sistema suporta o aumento repentino de tráfego. Imagine um site de notícias que se prepara para a cobertura de uma eleição; o pipeline executa testes de estresse para garantir que a página não saia do ar sob milhões de acessos simultâneos. A automação transforma a qualidade em uma característica intrínseca do processo produtivo, e não em uma fase posterior de inspeção. Ao investir em uma base sólida de testes automatizados, as empresas reduzem o retrabalho e as interrupções de serviço, construindo uma reputação de excelência técnica perante seus clientes.
A Infraestrutura como Código, ou IaC, é a prática de gerenciar e provisionar a infraestrutura de TI (como redes, máquinas virtuais e balanceadores de carga) por meio de arquivos de definição legíveis por máquina, em vez de configurações manuais em painéis de controle. Essa abordagem traz para a infraestrutura os mesmos benefícios que o desenvolvimento de software desfruta há décadas: versionamento, reprodutibilidade e automação. Com a IaC, a criação de um novo ambiente de produção torna-se tão simples quanto executar um script, garantindo que o servidor seja configurado exatamente da mesma forma todas as vezes, eliminando o erro humano e a deriva de configuração, onde servidores que deveriam ser idênticos acabam se tornando diferentes ao longo do tempo.
Imagine uma startup que precisa expandir sua operação para um novo país. Sem a IaC, os engenheiros teriam que configurar manualmente dezenas de servidores na nuvem, correndo o risco de esquecer uma regra de firewall ou uma versão de software específica. Com ferramentas como Terraform ou Ansible, a equipe utiliza scripts que descrevem toda a topologia da rede e as especificações dos servidores. Ao executar esses scripts, a infraestrutura é criada de forma idêntica à do país de origem em poucos minutos. Essa capacidade de escala sob demanda é fundamental para negócios que enfrentam crescimentos explosivos ou flutuações sazonais. Se um script de IaC foi testado e aprovado em um ambiente de desenvolvimento, a probabilidade de erro ao aplicá-lo em produção é mínima, o que aumenta drasticamente a estabilidade operacional.
Além da velocidade, a IaC facilita a conformidade e a auditoria. Como toda a infraestrutura está definida em código, é possível rastrear quem fez qual alteração e por quê, utilizando o histórico do sistema de controle de versão (como o Git). Se uma alteração na rede causou uma brecha de segurança, a equipe pode realizar o rollback para a versão anterior do código de infraestrutura de forma quase instantânea. Isso transforma a gestão de servidores de uma “arte mística” realizada por administradores isolados em uma engenharia transparente e colaborativa. No modelo DevOps, a IaC é a ponte que permite que desenvolvedores e operadores falem a mesma língua — a língua do código —, unificando a gestão de toda a pilha tecnológica e permitindo que a empresa opere com uma eficiência e agilidade sem precedentes.
O DevOps é fundamentado no princípio do aprendizado contínuo, onde o ciclo de feedback curto é essencial para o refinamento constante dos processos e do produto. Esse ciclo começa na concepção da ideia e permeia todas as etapas até o uso real pelo cliente. A agilidade não vem de trabalhar mais rápido, mas de errar pequeno e aprender rápido. Ao realizar lançamentos frequentes em pequenas doses, a equipe recebe feedback imediato do mercado, permitindo ajustar a rota antes de investir recursos massivos em funcionalidades que o usuário pode não valorizar. Esse processo de inspeção e adaptação constante é o que mantém a empresa competitiva em um cenário de mudanças rápidas e incertezas.
Um exemplo prático de melhoria contínua pode ser visto na gestão de um sistema de e-learning. A equipe decide lançar uma nova funcionalidade de gamificação para aumentar o engajamento dos alunos. Em vez de esperar meses para lançar o sistema completo, eles liberam uma versão simplificada de medalhas virtuais para um pequeno grupo de usuários (Canary Release). Através das métricas de monitoramento e de pesquisas rápidas, eles percebem que os alunos valorizam mais o ranking social do que as medalhas isoladas. Com esse feedback em mãos, a equipe altera o foco do próximo ciclo de desenvolvimento para fortalecer a interação entre os estudantes. Essa capacidade de pivô baseada em evidências reais economiza tempo e dinheiro, garantindo que o esforço da equipe esteja sempre alinhado com o valor percebido pelo cliente.
A melhoria contínua também se aplica aos processos internos das equipes. Através de reuniões de retrospectiva ao final de cada ciclo de entrega, os membros do time discutem abertamente o que funcionou e o que pode ser otimizado no pipeline de automação ou na comunicação entre as áreas. Talvez a automação de testes esteja demorando demais e precise ser paralelizada, ou talvez o processo de aprovação de segurança precise de critérios mais claros. No DevOps, nenhum processo é considerado perfeito ou estático. Essa cultura de insatisfação positiva com o status quo impulsiona a equipe a buscar constantemente ferramentas mais eficientes e formas de trabalho mais inteligentes, resultando em um software cada vez melhor e uma equipe cada vez mais motivada e produtiva.
No contexto do DevOps e de sistemas distribuídos modernos (como microsserviços), o monitoramento tradicional, que apenas indica se um componente está “vivo” ou “morto”, já não é suficiente. Surge então o conceito de observabilidade, que é a capacidade de entender o estado interno de um sistema complexo apenas observando seus outputs externos (métricas, logs e traces). A observabilidade permite responder não apenas a “o que está acontecendo?”, mas “por que isso está acontecendo?”. Em um sistema altamente conectado, onde um erro em um serviço pode ser causado por uma latência em outro serviço a quilômetros de distância, ter uma visão profunda e contextualizada é a única forma de manter o controle sobre o caos técnico.
Para ilustrar a observabilidade na prática, imagine uma plataforma de pagamentos globais. Um cliente reclama que sua transação falhou, mas o monitoramento básico indica que todos os servidores estão verdes e funcionando. Através da observabilidade, a equipe utiliza o rastreamento distribuído (Distributed Tracing) para seguir a jornada exata dessa transação específica através de dez microsserviços diferentes. Eles descobrem que, embora todos os serviços estejam funcionando, uma combinação específica de moeda e fuso horário causou um erro lógico em um componente de validação de impostos. Essa investigação cirúrgica, que levaria dias no passado, é resolvida em minutos graças à instrumentação adequada do software. A observabilidade empodera a equipe DevOps a dominar a complexidade, permitindo que eles inovem com segurança em arquiteturas modernas.
A implementação da observabilidade exige que o software seja construído para ser “observável” desde o início. Os desenvolvedores inserem pontos de coleta de dados que geram logs estruturados e métricas de negócio ricas. Esses dados são centralizados em ferramentas de análise que permitem correlações inteligentes. A observabilidade não é apenas uma ferramenta técnica, mas um pilar de confiabilidade que fortalece o relacionamento com o cliente. Quando a empresa consegue identificar e resolver um problema antes mesmo do cliente entrar em contato com o suporte, ela demonstra um nível de excelência e cuidado que gera lealdade. No DevOps, ser observável significa ter a clareza necessária para operar sistemas críticos com serenidade, transformando dados brutos em inteligência operacional que guia o crescimento sustentável do negócio.
Mesmo com os melhores processos DevOps, incidentes em produção são inevitáveis em sistemas complexos. O diferencial de uma organização ágil está em como ela reage a essas falhas. O gerenciamento de incidentes em DevOps foca na restauração rápida do serviço e, crucialmente, na prevenção de recorrências através da prática de Retrospectivas Sem Culpados (Blameless Post-Mortems). Essa abordagem parte do princípio de que ninguém vai trabalhar com o objetivo de cometer erros; portanto, falhas são sempre oportunidades de identificar fraquezas nos processos, nas ferramentas ou na automação, e não defeitos de caráter individual.
Suponha que um erro de configuração manual em um banco de dados tenha causado a perda temporária de acesso aos dados de clientes em uma seguradora. Em uma cultura tradicional, o administrador responsável seria punido. No DevOps, a equipe se reúne para analisar por que foi possível fazer uma alteração tão crítica de forma manual e sem uma rede de proteção. Como resultado da retrospectiva, eles decidem automatizar a configuração via IaC e implementar um teste de validação de esquema de dados no pipeline de CD. O foco é fortalecer o sistema para que ele seja à prova de erros humanos. Essa atitude remove o medo de inovar e incentiva a transparência, pois os colaboradores sentem-se seguros para admitir falhas rapidamente, o que é essencial para minimizar o tempo de inatividade.
Para que essa cultura floresça, o aprendizado da retrospectiva deve ser compartilhado com toda a organização. As lições aprendidas em um time podem evitar problemas similares em outras áreas da empresa. Além disso, as retrospectivas ajudam a priorizar o “débito técnico” — aquelas tarefas de melhoria de infraestrutura ou refatoração de código que muitas vezes são deixadas de lado em favor de novas funcionalidades. No DevOps, resolver a causa raiz de um incidente é considerado tão importante quanto entregar uma nova tela, pois garante a sustentabilidade do sistema a longo prazo. Essa gestão inteligente do fracasso é o que separa as empresas resilientes das que vivem em constante estado de crise, permitindo que a organização cresça com estabilidade e confiança.
À medida que as práticas DevOps amadurecem, muitas organizações adotam o Site Reliability Engineering (SRE), um modelo criado pelo Google que trata a operação como se fosse um problema de engenharia de software. O SRE é o DevOps levado ao seu limite técnico e organizacional, focando intensamente na escalabilidade e na confiabilidade absoluta dos sistemas. O engenheiro SRE utiliza ferramentas de automação para gerenciar frotas massivas de servidores, buscando sempre eliminar o “toil” (trabalho manual repetitivo e de pouco valor estratégico). A filosofia central do SRE é que a estabilidade é a funcionalidade mais importante de qualquer software, pois de nada adianta ter recursos inovadores se o sistema está fora do ar.
Um conceito chave do SRE é o Orçamento de Erros (Error Budget). A empresa define um nível de serviço aceitável (SLO), como “o site deve estar disponível 99,9% do tempo”. O orçamento de erro é o 0,1% restante. Enquanto esse orçamento estiver positivo, a equipe pode lançar novas funcionalidades com rapidez. Se o sistema sofrer muitas interrupções e o orçamento se esgotar, os lançamentos de novas funções são congelados e todos os esforços são direcionados para melhorar a confiabilidade. Isso equilibra de forma matemática e objetiva a tensão natural entre a velocidade desejada pelo desenvolvimento e a estabilidade exigida pelas operações. É uma maneira inteligente de garantir que a agilidade não destrua a qualidade da experiência do usuário.
No dia a dia, o SRE aplica práticas de engenharia de caos (Chaos Engineering), que envolvem injetar falhas deliberadas no sistema em produção — como desligar um servidor aleatoriamente — para verificar se o software é capaz de se recuperar sozinho de forma automática. Imagine um sistema de logística que desliga automaticamente um centro de processamento para testar se os pedidos são redirecionados corretamente para outro sem intervenção humana. Esse nível de sofisticação técnica garante que a empresa esteja preparada para o inesperado. Ao adotar princípios de SRE, as organizações DevOps elevam sua maturidade operacional, transformando a tecnologia em uma vantagem competitiva inabalável, capaz de suportar cargas globais com uma confiabilidade que inspira total confiança nos clientes e parceiros de negócio.
